A répondu dans un fil de discussion

@vv I wish I could find those programs and restore them. 
There are plenty of fun ones, like the 3D airplane model.

@vv I wish I could find those programs and restore them.
There are plenty of fun ones, like the 3D airplane model.
Who wants to pay me to work on #LispMachine #CADR #LispM?
"Compiled to microcode"?
Sort of... and sort of not.
Probably meant to say "compiled to machine code", like any other machine and compiler. The machine instructions were quite readable, at least after getting used to them. Mostly a stack machine with 256 registers to buffer the top of stack.
MIcrocode is another matter.
LMI had a microcompiler for a while, which could take a (smallish) lisp function and create a single instruction to execute it. Then you'd create a "defsubst" -- a function that would be open-coded -- to persuade the compiler to emit that instruction.
However, this only saved time if instruction fetch and decode dominated execution in normal machine code. It was kind of tricky. (Their marketing folk sure loved it, though.)
Symbolics never released a microcompiler. The micromachine (for the L-machine, that is) had a much wider microinstruction word (sort of like VLIW stuff?). That meant there was much more parallelism going on for each microinstruction. That meant there was no straightforward microcompiler.
Later, the I-machine series no longer had a writeable control store for microcode. It was all in ROM, and that worked pretty well.
The Sunstone chip, the next Symbolics architecture, was going to be a RISC version of all this with no microcode anyway. It was cancelled the day it taped out for its first S-machine chip, sadly.
(And yes, the architectures of the L-, I-, and S-machines were spelling out LISP. The joke was the P-machine was going to be the "penultimate, pocket, parallel" architecture.)
That's distinguished from the CREF editor that I wrote in 1984, while on leave from my work on the Programmer's Apprentice to do a summer's work at the Open University.
CREF (the Cross-Referenced Editing Facility) was basically made out of spare parts from the Zwei/Zmacs substrate but did not use the editor buffer structure of Zmacs per se. If you were in Zmacs you could not see any of CREF's structure, for example. And the structure that CREF used was not arranged linearly, but existed as a bunch of disconnected text fragments that were dynamically assembled into something that looked like an editor buffer and could be operated on using the same kinds of command sets as Zmacs for things like cursor motion, but not for arbitrary actions.
It was, in sum, a hypertext editor though I did not know that when I made it. The term hypertext was something I ran into as I tried to write up my work upon return to MIT from that summer. I researched similar efforts and it seemed to describe what I had made, so I wrote it up that way.
In the context of the summer, it was just "that editor substrate Kent cobbled together that seemed to do something useful for the work we were doing". So hypertext captured its spirit in a way that was properly descriptive.
This was easy to throw together quickly in a summer because other applications already existed that did this same thing. I drew a lot from Converse ("CON-verse"), which was the conversational tool that offered a back-and-forth of linearly chunked segments like you'd get in any chat program (even to include MOO,), where you type at the bottom and the text above that is a record of prior actions, but where within the part where you type you had a set of Emacs-like operations that could edit the not-yet-sent text.
In CREF, you could edit any of the already-sent texts, so it was different in that way, and in CREF the text was only instantaneously linear as you were editing a series of chunks, but some commands would rearrange the chunks giving a new linearization that could again be edited. While no tool on the LispM did that specific kind of trick, it was close enough to what other tools did that I was able to bend things without rewriting the Zwei substrate. I just had to be careful about communicating the bounds of the region that could be editing, and about maintaining the markers that separated the chunks as un-editable, so that I could at any moment turn the seamed-together text back into chunks.
Inside CREF, the fundamental pieces were segments, not whole editor buffers. Their appearance as a buffer was a momentary illusion. A segment consisted of a block of text represented in a way that was natural to Zwei, and a set of other annotations, which included specifically a set of keywords (to make the segments easier to find than just searching them all for text matches) and some typed links that allowed them to be connected together.
Regarding links: For example, you could have a SUMMARIZES link from one segment to a list of 3 other segments, and then a SUMMARIZED-BY link back from each of those segments to the summary segment. Or if the segments contained code, you could have a link that established a requirement that one segment be executed before another in some for-execution/evaluation ordering that might need to be conjured out of such partial-order information. And that linkage could be distinct from any of several possible reading orders that might be represented as links or might just be called up dynamically for editing.
In both cases, the code I developed continued to be used by the research teams I developed it for after I left the respective teams. So I can't speak to that in detail other than to say it happened. In neither case did the tool end up being used more broadly.
I probably still have the code for CREF from the time I worked on it, though it's been a long time since I tried to boot my MacIvory so who knows if it still loads. Such magnetic media was never expected to have this kind of lifetime, I think.
But I also have a demo of CREF where took screenshots at intervals and hardcopied them and saved the hardcopy, and then much later scanned the hardcopy. That is not yet publicly available, though I have it in google slides. I'll hopefully make a video sometime of that just for the historical record.
3/n
(continued from previous)
By the way, I was misremembering which of the tools I worked on was called KBEmacs, since that name was created after my involvement.
In 1981-1984, I worked on the Programmer's Apprentice, which was a Zmacs-based application that edited code using knowledge-based tools. There is a close analogy here to using co-pilot today. But ultimately it's an application that's really layered atop existing tech and that isn't a fundamental change to the structure of Zmacs itself.
The integration is a little tighter than a shell buffer in Emacs, which is not fundamentally about changing the structure of Emacs but rather just about picking up input and depositing output from a tool that's doing something separate to text.
A notable difference from the way co-pilot-like tools work is that there was an actual understanding/model of what it was doing. It was not a stochastic parrot, in other words. It did a real structural analysis of the code and so was not guessing. It was obviously working on a machine that was less sophisticated (certainly slower) than modern tools and there were a host of other limitations.
And this gets to a point I've often made about AI in the modern world, as it requires gigantic data centers and how a single query is said to sometimes consume a whole liter of fresh water that could be sustaining the population of human beings on the planet: The squirrels in my yard, though not as sophisticated in English as ChatGPT, do things that are probably smarter an with a better model of what they are doing. I can put up fairly sophisticated guards to keep them from the birdseed in the birdseed, and they will figure out how to thwart that, and yet it does not cost them in terms of energy or fresh water nearly what it costs to run ChatGPT.
The point here is simple but important: Intelligence, real intelligence, not the kind of faux thing that LLMs offer, uses LESS energy. A foundation that is massively energy-consuming is not a good foundational element around which to build something that uses less energy.
So while the Programmer's Apprentice was a demonstration of a path that could have been pursued, and less sophisticated in many ways, it was at least pursuing tech that did not have arbitrary consumption of resources at its core.
But that illustrates something else that's important to understand about evolution that I often say: You can be the best adapted lizard in the desert, but if you cannot swim on the day of a flood, your evolutionary line will be done for. That doesn't prove you were a bad lizard, it's just that nature is harsh in ways that are arbitrary and of-the-moment and it's not the fittest that survive, but those that have invested in the series of high-order-bit that are chosen by lottery to dominate as the thing-of-the-moment on each day of history.
So the Programmer's Apprentice, KBEmacs, and even the Lisp Machine did not survive, but other things did, and not necessarily because they were bad ways of thinking about code or editing, but because of other factors that are probably really boring, like price points of hardware on which these ideas ran.
So that is the context in which KBEmacs existed.
2/n
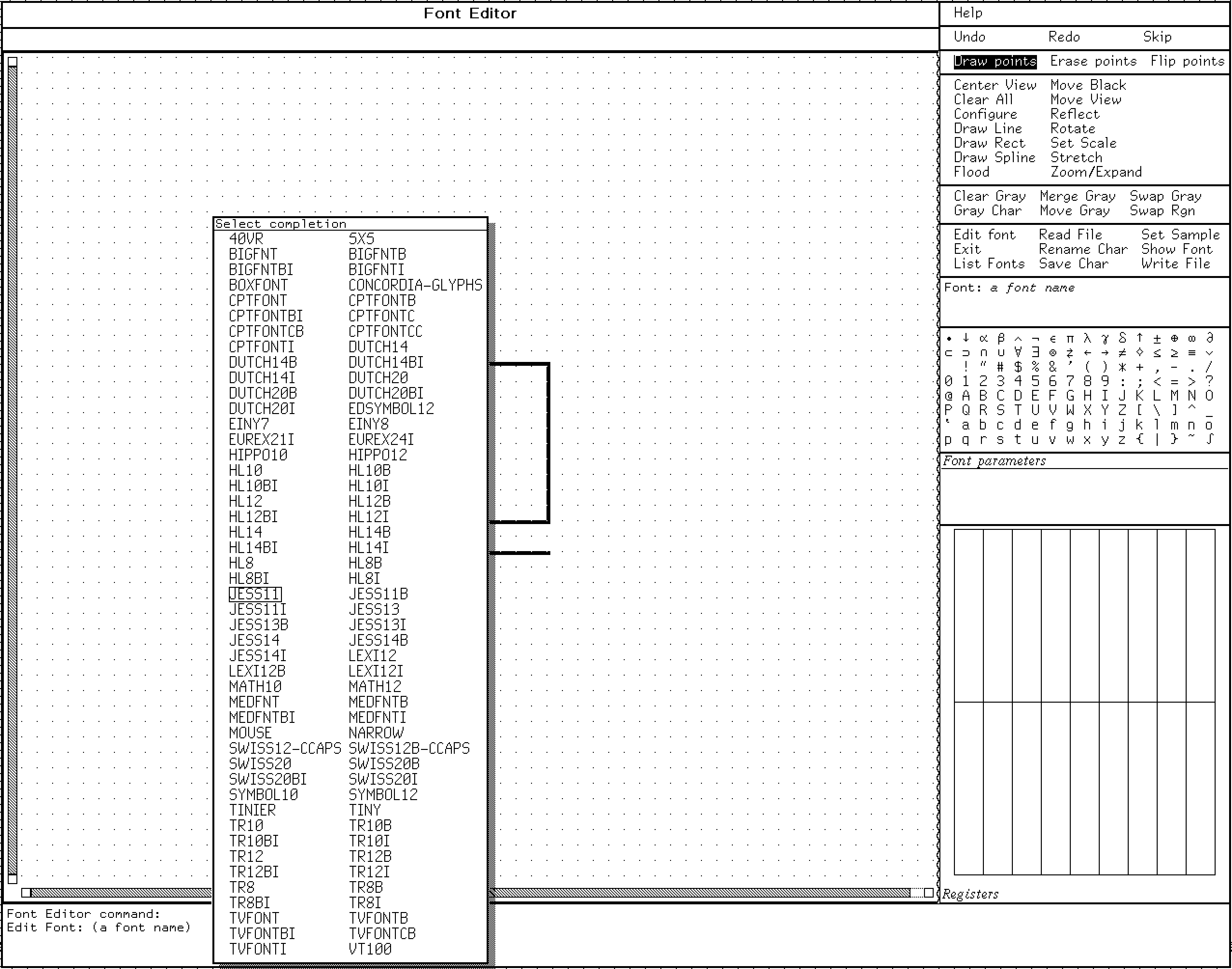
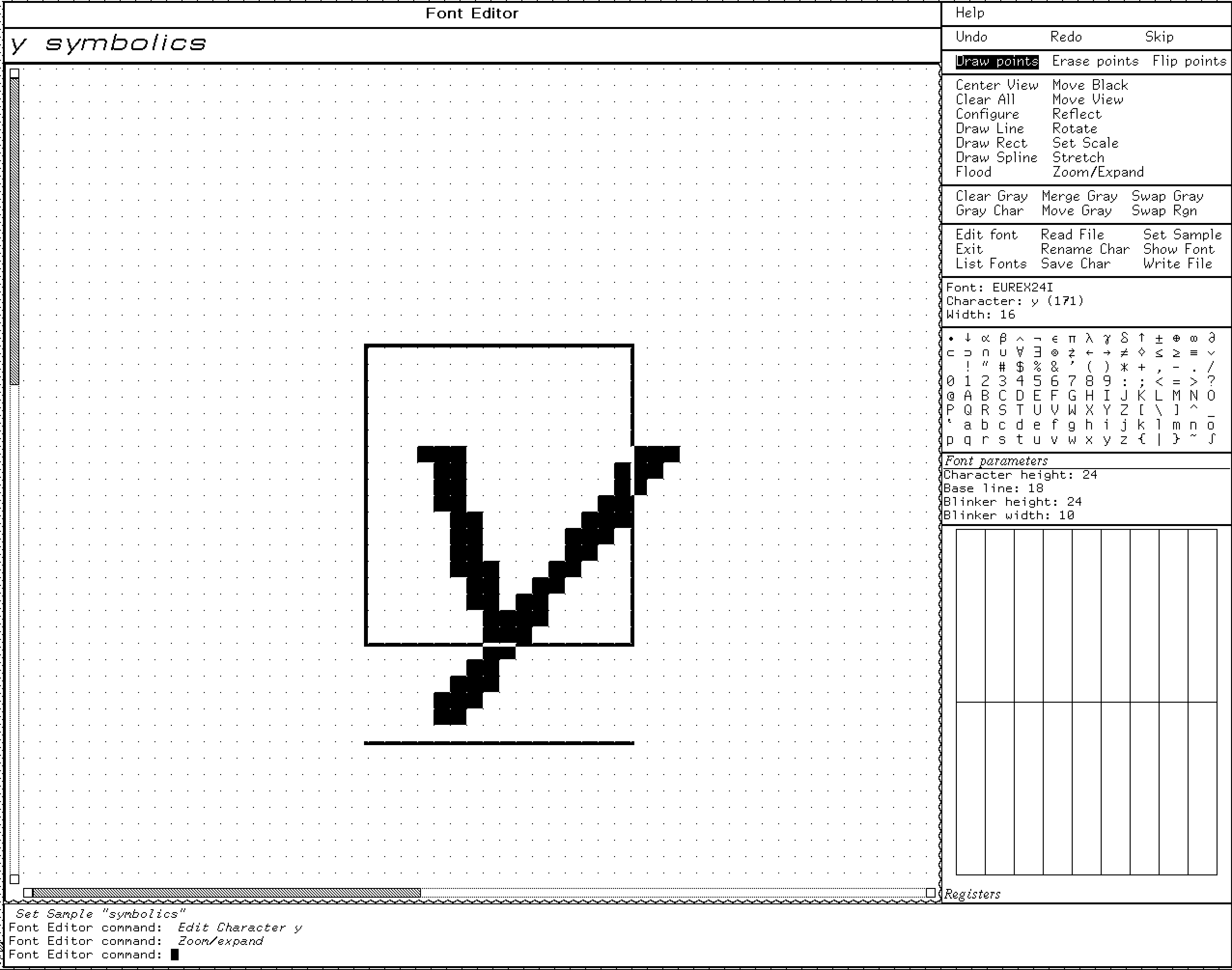
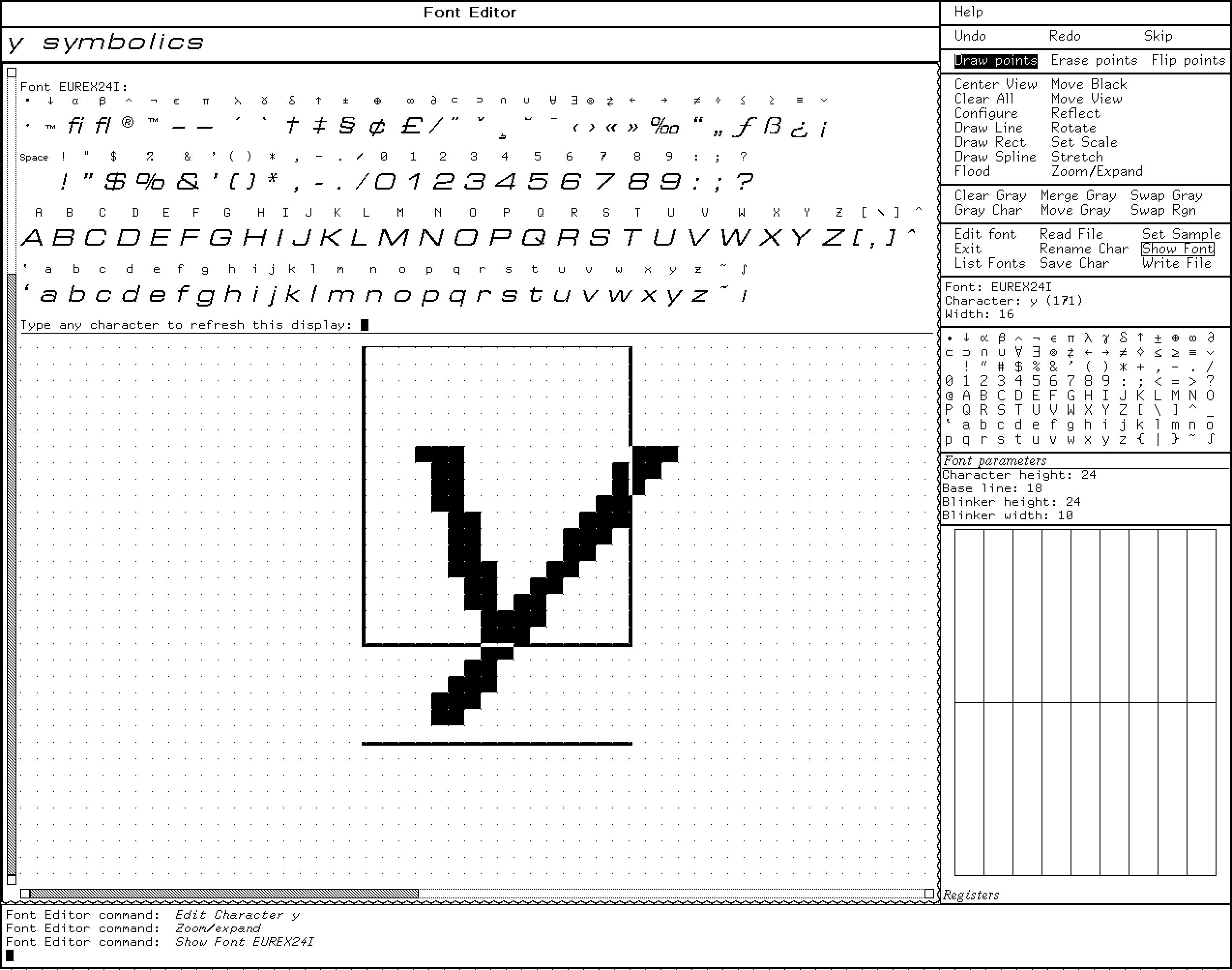
The Bitmap Font editor in #symbolics Genera, a #lispmachine
Anyone know if the ice cream at toscanini is any good? #LispM #LispMachine hackers

What should I write about #LispMachine #LispM?
@jxself They had two MIT CADRs. RIP. #LispM #LispMachine
No clue.
I did use CADR lisp machines*, but I am not sure I ever used the remote debugger. I don't think I did.
I can speculate a little, but I emphasize that I know exactly zero about this and am just completely guessing.
The form of the text is like that of an FTP or HTTP response code: a three-digit code and some other text that perhaps doesn't matter. If it's related to that, 105 is in the 1xx range, which is informational. FOOBAR in that case may just be someone inserting non-null text for something that had no specific better text.
Searching an early draft of the LispM manual (suitable for CADR) at http://www.bitsavers.org/pdf/mit/cadr/Weinreb_Moon-Lisp_Machine_Manual_Jan_1979.pdf for "105 foobar" does reveal a match, but it's in the description of si:lisp-top-level1, where it says:
«Preliminary Lisp Machine Manual, page 267, The Lisp Top Level:
si:lisp-top-level1
This is the actual top level loop. It prints out ·"105 FOOBAR" and then goes into a
loop reading a form from standard-input. evaluating it. and printing the result
(with slashification) to standard-output. If several values are returned by the form
all of them will be printed. Also the values of *, +, and - are maintained (see
below).»
Based on all of this, I'm reaching even further but wondering if perhaps someone wanted to use the informational output of the si:lisp-top-level1 command having been successfully invoked as input on the other end of some pipe saying to go ahead and start a debugger session.
As I said, just a wild guess. I could be VERY wrong. :)
*I used the CADR lisp machines at MIT in the early 1980s as part of the programmer's Apprentice project, where I named machine Avatar (long before the movie, more inspired on a theme akin to the Sorcerer's Apprentice) and at the Open University (summer 1984, I think) in Milton Keynes, UK, where I named my machine Alan Turing.
(Cadrs were hand-built machines, as I recall, so they were each much more like individuals and their naming was much more important than machines that were mass produced.)
The name Turing was chosen for the machine at the OU because of the building we were in, which was referred to as "Turing's hut". It was said to be a temporary building erected in World War II where Turing did his work. (This was long after WWII, but MIT also had "temporary" buildings built for the war that survived much longer.) I've more recently struggled to reconcile the claim that Turing worked in that building against the information in the movie The Imitation Game, which puts Turing's work in Bletchley Park, but the OU is not far from Bletchley Park, so there's probably some element of truth in one or the other. In that time (mid 1980s), Turing's contribution was more obscure and no one really questioned such details. It was just nerdy trivia.
#LispM curiosity .. in the CADR Console debugger, to start the remote machine one types "105 FOOBAR" -- can anyone explain why? #LispMachine

Interested in gauging the value of my Symbolics MacIvory 3 (4MW of memory; 4.9MB SCSI Drive w/Genera software installed; Genera Media included). I know what I paid to acquire it in October of 2020, but I’m not sure what the potential value is now. Any thoughts on how to assess the value?
@abuseofnotation #LispM did nothing magical, they are just normal computers (code gets compiled, that code gets run); what it sounds like you are thinking of is dynamic programming and memoization? Where intermediate results are cached, and not recalculated.
Join us now and hack some #LispMachine -- you'll be a parenthesis. #LispM hacking. Bored? Join #lispm @ Libera on IRC.
Anyone interested on working on the #CADR / #LispMachine? #LispM I need HDL hackers ideally ... but the more the merrier!
I'm also going to tie in:
- #gopherMOO #VirtualReality (&lineage) as the present and pragmatic way of programming
You can find gopherMOO at https://larrymasinter.net/ ( @masinter )
- #climate predictability as a requirement for future planning and bits an arguement I was having with @HeavenlyPossum et al about the possibility or impossibility of project management
- My #vhdl is aimed at @amszmidt #lispm but I'm not sure he's sure we are converging yet (no fear).
#lisp #lispmachine #lispm #symbolics
A Graphics Editor on a Lisp Machine, changing the attributes of a circle.