

Summer  read: a new paper on model-based clustering just appeared in Computo!
read: a new paper on model-based clustering just appeared in Computo!
Julien Jacques and Brendan Thomas Murphy publish a new method for clustering multivariate count data. The method combines feature selection and clustering, and is based on conditionally independent Poisson mixture models and Poisson generalized linear models.
On simulations, the Adjusted Rand Index (ARI) of the model with selected variables is close to the optimal ARI obtained with the true clustering variables.
The paper and accompanying R code are available at https://computo-journal.org/published-202507-jacques-count-data/
 or the selected variables (on the right). The selection of variables always provides an ARI closes to the optimal ARI.")




 Greg Cocks
Greg Cocks 
. Central Park in Bello (B). Parques del Río Medellín (C). Arkadia Shopping center; (D). Peldar Plant (E). La García water supply reservoir (F). Conasfaltos dam (G). La Ayurá stream basin in Envigado (H). Central Park in Bello (I). Avenida Regional Norte (J). Vía Distribuidora Sur.")

 between the valleys of the Magdalena and Cauca rivers. Data were acquired from ALOS PALSAR Terrain Corrected and data from IGAC.")

 Hi all
Hi all 






![snapshot - 1913 housing advertisement for the Palm Haven neighborhood in San Jose. 1913 is several years before Buchanan found “restricted districts” based on race unconstitutional, and the advertisement emphasizes the “restricted district[].” Palm Haven construction dates straddled Buchanan. It was developed by Thomas Herschbach who came to be responsible for 161 racial covenants in the County](https://files.techhub.social/media_attachments/files/113/347/153/039/429/065/original/0b7758570a865277.jpg "snapshot - 1913 housing advertisement for the Palm Haven neighborhood in San Jose. 1913 is several years before Buchanan found “restricted districts” based on race unconstitutional, and the advertisement emphasizes the “restricted district[].” Palm Haven construction dates straddled Buchanan. It was developed by Thomas Herschbach who came to be responsible for 161 racial covenants in the County")
![snapshot - portion of deed - Although racially restrictive covenants are no longer legally enforceable and are considered illegal under the Fair Housing Act today, they still exist in thousands, possibly even millions, of historical property records in California. One such example, found in a 1940 real property deed from Santa Clara County’s archives, contains the following discriminatory language: “No persons not of the Caucasian Race shall be allowed to occupy, except as servants of residents, said real property or any part thereof.” The deed further specifies that “[t]hese covenants are to run with the land and shall be binding on all parties,” thereby affecting not only the tenants at the time but also the potential future owners of the land.](https://files.techhub.social/media_attachments/files/113/347/153/037/909/858/original/5cae8b68202478cd.jpg "snapshot - portion of deed - Although racially restrictive covenants are no longer legally enforceable and are considered illegal under the Fair Housing Act today, they still exist in thousands, possibly even millions, of historical property records in California. One such example, found in a 1940 real property deed from Santa Clara County’s archives, contains the following discriminatory language: “No persons not of the Caucasian Race shall be allowed to occupy, except as servants of residents, said real property or any part thereof.” The deed further specifies that “[t]hese covenants are to run with the land and shall be binding on all parties,” thereby affecting not only the tenants at the time but also the potential future owners of the land.")










 [TTT] Deviner la Tchéquie
[TTT] Deviner la Tchéquie 


 Rechercher avec
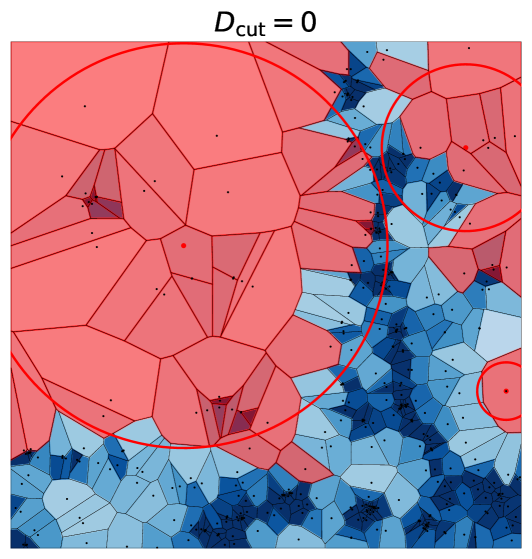
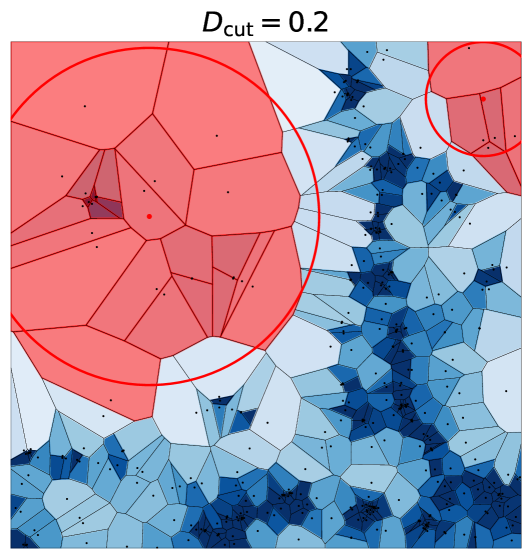
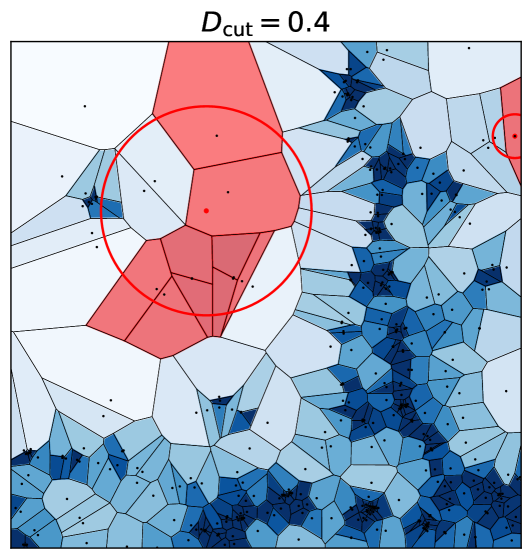
Rechercher avec  ) d'anciennes partitions territoriales en mobilisant l’algèbre linéaire pour classifier/clusteriser des flux
) d'anciennes partitions territoriales en mobilisant l’algèbre linéaire pour classifier/clusteriser des flux Dans Néocarto
Dans Néocarto 






.")